March + April Challenge: Daily Coding (aka Adventures in AI)
by Cody on 2023-05-05 filed under experiments

For March and April, I wanted to try to build a habit focused on creation. That habit? Writing code every day, building towards an interesting side project. The result? A fun generative AI project called plantae.ai.
A Month of Coding
Coding and I have a history together. When I first encountered the Internet in the mid 90s, I immediately wanted to build things. The great thing about the Internet is, you can. You can just build things and they can just run forever, no matter if they're any good or not. It's unlike anything else. As soon as I figured this out, I knew I wanted to do that until my fingers ran out of typing juice. And I have! Well, I did for years, then I took a detour into the world of management, to the point I don't code anymore. But what if I got back into it? Would it still be fun? Would I still be good at it?
Why Now?
I am trying to make 2023 my year of monthly experiments. January was daily meditation (verdict: 👍). After February's personal finance experiment (verdict: 👎), I realized that my discipline and attention to detail has limits. And my limit is just short of mastering personal finance. If I'm going to take the time to do something every day for a month, I need to enjoy it and get some meaning from it. A month of coding had been percolating in my mind since the start of 2023, but the tedium of personal finance really pushed this to the top of the list.
The Experiment
Alright, here's the experiment: write code every day. And not just random "Hello World" each day, but something that builds towards an interesting application. The culmination of a month of coding should be a working app on the Internet.
At the same time I was thinking about coding for a month, I was thinking about a couple of other things. First, I was reading Richard Powers' The Overstory. Great book. If I had to summarize it in 1 word, I'd go with: plants. I was also thinking about generative AI, where so much is happening. What if I combined the two? While everyone else on the Internet is making terrifying deep fakes of celebrities and world leaders, I'd do some nice computer things with noble firs.
How Does It Work?
I knew upfront that I'd devote my coding towards a side project rather than my day job. Why is that? After all, my job title has the word 'engineer' right there in VP of Engineering! I had a couple of reasons.
First, I try to devote my working hours to whatever is most valuable for the company. My employer pays for my time and they are going to get their money's worth. (Career tip: it's crucial to keep it that way, or your employer will stop paying for your time.) The most valuable use of my time from the company's perspective isn't writing code, it's running things, unblocking, prioritizing, and all that good stuff.
Second, it's easy for well-intentioned managers to try to help out on the coding side when they have a bit of free time. Then, actual management tasks pop up, managers jump on them, and they inadvertently block these changes getting out the door. I don't want to inflict that on anyone. So, I'd focus purely on side projects after working hours using my own resources.

Here's something that's not surprising: it's hard to code every day. It can be hard intellectually to know what to do next, especially when you get stuck. It can also be hard logistically. My typical day has me doing work stuff + family stuff from 7am - 8pm every day. At 8:01pm, am I itching to fire the editor and write some code to solve more problems? No, dear reader, that is not the case! There were plenty of week days where I did something in 2 minutes that barely qualified as coding, like an update to the README or freezing project dependencies. There were other days where family or work responsibilities went later than 8pm, so I punted on coding for the day. Do I feel bad about this? No.
Ultimately, the only way I could make larger changes was on the weekend, when I had more autonomy over my schedule and longer blocks to concentrate. Then throughout the week, I'd peck away at tiny, incremental improvements. Or I'd just update the README. The progress was slow, but steady that way.
Remember that part in the intro where I said, "The culmination of a month of coding should be a working and interesting app on the Internet"? Well, as anyone who's ever built anything can attest, shipping is the hard part. By the end of March, I had a halfway interesting app with a lot of bad data and a charming habit of timing out on 50% of requests. Halfway interesting and halfway working wasn't good enough. I decided then to expand the experiment into April. Maybe that's moving the goalpost, but I was learning and having fun. And I'm pretty sure this is not the first software project to suffer a schedule slip.
What Happened?
People of the Internet, I direct you to plantae.ai. I collected tens of thousands of plants. I organized them into a basic taxonomy. For each plant, I generated art in the style of Leonardo da Vinci using Stable Diffusion, then I generated a 1 paragraph summary using OpenAI's API. There's more generated text for each division, class, order, genus, etc.

I am going to do a separate writeup on the technical learnings from this project, so I will spare you the gory details. But I do want to share a few quick highlights.
- The developer ecosystem around AI is amazing. Training and then generating interesting art / text is easy. I found the APIs and docs for Stable Diffusion and OpenAI's text completion API to be clear and easy to follow. It's also cheap! I spent $20 in total for my art and text generation on 2k plants, across multiple generation runs as I tweaked the models. I didn't cover the entirety of my dataset (58k plants remaining!), but just enough to prove this works.
- The hardest part of the project was actually building a structured and correct dataset of plants. I scraped thousands and thousands of webpages to get structured, taxonomical data on 60k plants because I couldn't find an open source database. There are still many parts of this data that are just... horrible. Data correctness (and thus model fidelity) seems to be a very hard problem at scale in this domain. But on the bright side, I now have a heck of a task queue system for all this scraping.
- The second hardest part was getting all of this into production and serving traffic. I wanted to explore on the cheap here too, so I went with packaging everything into a Docker container then serving that on the fly via Google Cloud's Cloud Run. Site performance isn't going to blow anyone away, but again, it's so cheap! I was ok with latency, but not ok with timeouts. Solving those took a lot of fiddling across the Dockerfile, nginx, gunicorn, and the liveness probe. I was particularly impressed with Cloud Run's integration with Cloud Build for CI/CD. I granted it read access to my github repo, pointed it to my Dockerfile, and I had legit continuous deployment about 5 minutes later. According to the GCP console, I have spent literally $1 on infrastructure so far.
- I chose not to get fancy with core tech stack given all the other experimentation. Instead, I favored things I already knew well. For me, that proved to be the simplest Javascript I could write for DOM manipulation + Bootstrap for the UI + Django for the backend + good old sqlite for the database.
- As cool as all the generated art and text is, there's a solid 5-10% of the artifacts that are highly unreliable. I'm sure part of that is the data I used for my own models. But there is also just unpredictable weirdness. Here's a great example. Why did Stable Diffusion create an image of a nice Renaissance lady for a perennial flowering plant found in India, East Africa and the Philippine? How would you even find these anomalies at scale?
- As with all crazy side projects, the most expensive parts were A) my time and B) the domain ($70). Maybe the only people getting rich on the AI craze are domain registrars. But I stand by that domain name and will include it in my will.
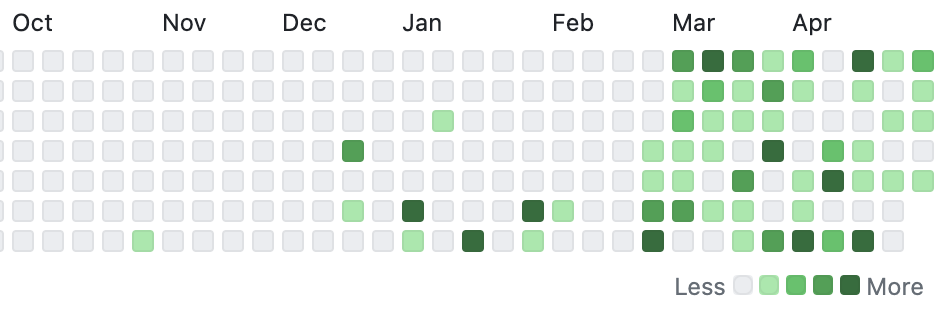
Ok, but what about the experiment itself? Did I code every day? I took a few days off as said above, but overall, I had 51 commits in March and 39 in April, across 79% of the days in those months. Github activity graph don't lie. Most important, I learned, had fun, and built this weird little website.
Keep It or Kick It?
Will I continue coding every day? Realistically, no. I want to continue this side project, as it's been a fun way to explore new technology and learn a lot about plants. I have a ton of ideas here (and if you also have ideas or questions, I'd love to hear them!). But I am not going to commit to daily activity here and optimize for my github commit history.
What's Next?
Oh man, I don't know what the next monthly experiment will be. The only real requirement at this point is that it needs to be easier than coding every day, like daily flossing. I will come up with something and report back in a month.